Inference in the Wild
Practical lessons, failure modes, and playbooks for measuring and building intelligent systems.
Inference in the Wild is the practical series within my Inference & Intelligence Lab. This series focuses on what happens when theory meets reality: messy data, multiple stakeholders, imperfect experiments, model evaluation traps, and the day-to-day decisions that determine whether an analysis is actually useful.
What you’ll find here
- Statistical inference in practice: common misconceptions, testing pitfalls, and interpretation traps.
- Causal inference beyond the basics: real-world designs, multiple treatments, interference, and operational constraints.
- Machine learning & measurement: where modeling and evaluation collide (and what to do about it).
- GenAI evaluation: comparative evaluation, benchmark design, and practical guidance for making results trustworthy.
- Practical artifacts: toy simulations, sanity checks, lightweight frameworks, and decision-oriented writeups.
If you like posts that explain why something fails, how to diagnose it, and what a better default looks like, you’ll feel at home here.
📥 Subscribe
If you want new posts with downloadable PDF and podcast episodes in your inbox, subscribe to my newsletter on Substack.
📚 Blog Posts
Below are all posts in this series, sorted by date.

EP3: The Causality Gap — Measuring the True Impact of Voluntary Adoption in Digital Marketplaces
observational causal inference
randomized encouragement design
instrumental variables
DoubleML
LATE
EP2: Build the Camera — How Measurement Design Guides Statistical Testing
experimentation
sensitivity
measurement design
rank transformation
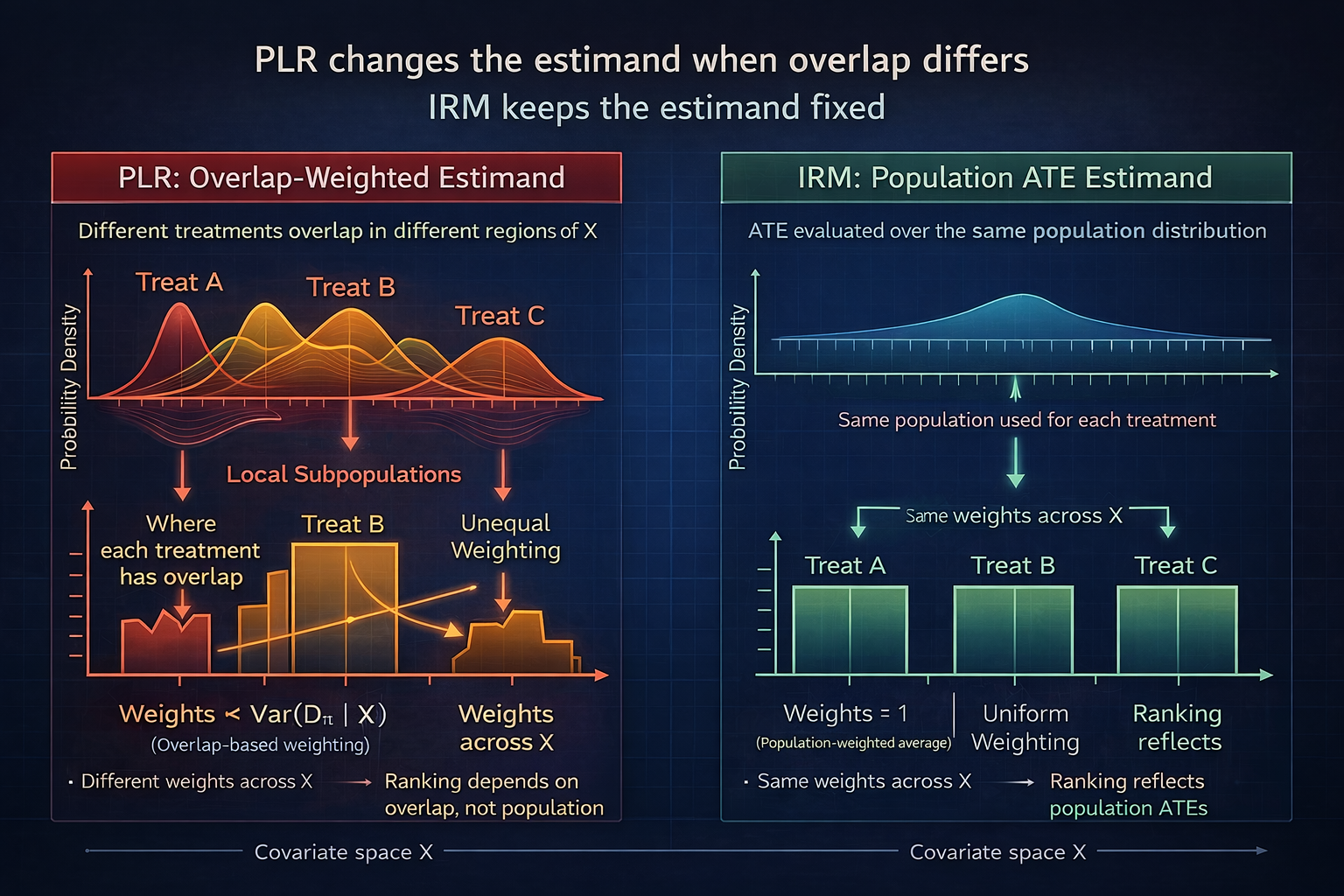
EP1: Why PLR Fails with Multiple Discrete Treatments
observational causal inference
estimation
estimand
overlap
DoubleML
estimator
No matching items